Arm Moves Compute Closer to Data

Arm is committed to maximizing the value of Internet of things (IoT) data by enabling compute as close as possible to where data is generated. In achieving this, we focus on three key areas within compute infrastructure: the endpoint, the edge and computational storage.
Why is it so important to move compute closer to data? It comes down to the fact that in so many IoT use cases, the value of data can be measured in milliseconds. From emergency healthcare to monitoring gas flow to predicting traffic collisions, any delay in extracting insight reduces the value of that insight—potentially to zero.
Consider then that the level of compute required to extract that value has traditionally been found only in powerful cloud data centers. With the clock ticking, data must be transferred from endpoint to cloud over potentially thousands of physical miles. The latency introduced in doing so limits that data’s value significantly while putting great strain on the overall infrastructure and increasing energy (and therefore cost) usage. Ultimately, it can make or break the value of a use case.
This problem would only get worse as more and more IoT sensors come online, sending potentially thousands of gigabytes of data per day upstream.
Arm recognizes that for the IoT to succeed in its aims to create a better world using data, the industry must focus its efforts in moving compute closer to data than ever before.
In many cases, that means enabling capable compute on the endpoint device itself. In others, it’s about putting compute where it makes the most sense; be it the edge, within computational storage or elsewhere in the network infrastructure.
The Endpoint

Data begins at the endpoint. It is generated, constantly and in great abundance by industrial sensors, cars, smartphones, security cameras, wearables and hundreds of other endpoint device categories within the IoT.
By giving endpoint devices the ability to process their own data, we ensure the lowest time-to-value of that data and therefore the greatest insight. Arm Cortex processors and Arm Ethos ML processors enable these processes on even the most restricted IoT devices, from traditional workloads to sophisticated endpoint AI and ML algorithms, putting compute closer to data.
In doing so, we also enable new ways to manipulate sensor data at the endpoint. We call this sensor fusion: the ability to aggregate data from multiple sensors within a device (but also potentially data from other nearby devices or less time-critical data from the cloud) and infer ever deeper meaning.
For example, an IoT device used to monitor the health of an industrial electric motor might traditionally monitor the RPM for fluctuations. In industrial applications such as this where machines are under extreme load, these failures can occur almost instantly and cause significant damage to machinery: in predicting that failure, every second counts.
A modern, AI-enabled device might employ sensor fusion, combining RPM data with data from voltage, vibration and sound sensors in real-time in order to pre-empt failure long before it happens.
Endpoint AI: Read more
Discover how Arm is enabling AI for IoT at the endpoint with the Arm Cortex-M55 CPU and Arm Ethos-U55 NPU
The Edge

By putting high-performance edge compute closer to data, we can ensure that even the most complex data workloads can be processed as quickly as possible. Residing within relatively close physical proximity to endpoint devices (for example, in the base station of a cell tower), edge servers reduce latency to near-zero and retain that critical time-to-value while maximizing data privacy and reducing energy costs.
Analyst house Omdia, which defines the edge as any location with a 20-millisecond (ms) round trip time (RTT) or less to the endpoint, predicts that edge server shipments will double by 2024.
Edge servers have a growing role in not only handling the flow of data but processing that data too. In most cases, this new wave of performant edge servers contains much of the same compute power found in cloud data centers, albeit far closer to the endpoint.
We can also extend the benefits of sensor fusion by pooling data from multiple IoT devices: an edge server presiding over the factory in our electric motor example above might aggregate data from multiple motor devices in order to spot patterns and better predict chain-of-event failure in real-time.
Another example is an ANPR/ALPR traffic camera, recording car license plate numbers. The camera itself might employ endpoint AI in order to analyse video frames and identify the license plates, sending the license plate (rather than any video data) to the edge server.
From here, an AI edge server might aggregate license plate data from hundreds of other nearby traffic cameras and compare it with a database of stolen vehicles to track a car as it moves across state, predict the vehicle’s trajectory and suggest roadblock locations to law enforcement.
Edge AI: Read more
Read more about how Arm is bringing intelligence closer to the edge through the Arm Neoverse family
Computational Storage

However, the example above has its own roadblock. Like many IoT devices, the endpoint traffic camera and edge server will contain a storage device. The camera will use this device to store raw traffic video; the edge server will use it to store license plate information, as well as information about the cameras it needs to communicate with and other operational data.
In both cases—and in the case of any compute device that employs external storage—the speed at which data can be processed is limited by the speed at which it can be stored to, and called from, storage.
In a conventional compute system, the CPU must request blocks of data from the storage. Only once that block of data has moved into memory can the CPU access the specific element of data it needs. This potentially results in a CPU retrieving large quantities of data from storage into memory in its search for a particular data element.
This bottleneck is addressed in the computational storage model, which adds powerful compute into the storage device itself, putting compute closer to data than ever.
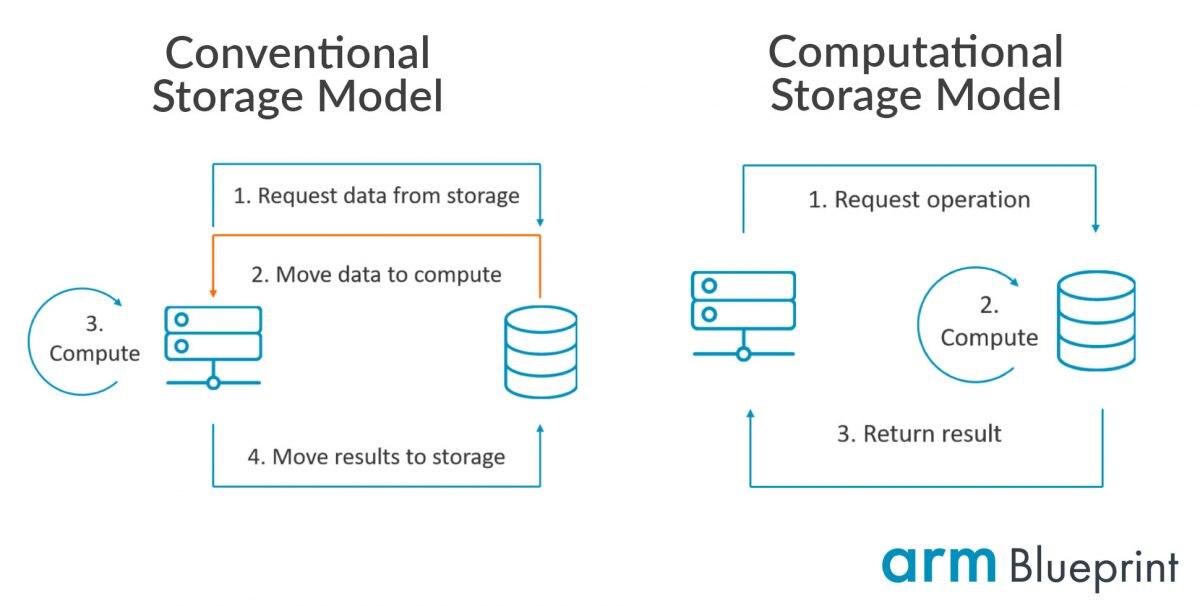
While conventional storage devices already contain a CPU to control storage functions, computational storage adds the capability to process non-storage workloads—such as the processing of data directly on the storage device.
In doing so, the main compute device no longer needs to request blocks of data: it requests an operation to be performed on the data, with only the computed result returned. In the case of an ALPR traffic camera, that might mean requesting all the license plates beginning with a certain letter.
The compute within the storage device would sort through its data and only send the relevant results back to the main compute device, significantly reducing the bandwidth required, and time taken, to process the data. And by reducing the movement of unencrypted data by enabling it to be processed directly on the drive with security in place, computational storage ensures that data remains as secure as possible.
In many cases, the compute performed on a computational storage CPU will be traditional in nature. Yet it’s entirely possible to run ML workloads, too—either natively on the CPU or via an NPU (neural processing unit). Continuing the above example, this might enable the storage device to identify all license plates beginning with a certain letter—but only on blue sedans. The more intelligence we add, the more complex the inference and the more value we can extract from data.
Computational Storage: Read more
Discover how the Arm Cortex-R82 CPU can power the next generation of computational storage devices.
Reducing latency, from miles to microns
Edge compute reduces the time it takes to process data sent upstream by potentially thousands of milliseconds. Endpoint compute reduces this even further by placing the compute on the device itself. And computational storage removes that final bottleneck between where data is computed and where it is stored.
Each of these technologies share the same key benefits: by putting compute closer to data, we gain reduced latency, faster inference, greater value, lower overheads, greater energy efficiency, greater privacy. It’s these fundamental values that Arm has invested in across its full range of IP. In doing so, we’re ensuring that the incredible amount of data being generated by the IoT every day is not wasted: time-to-value of data is maximized, and real insight can be drawn.
Read more about how Arm IP makes it possible to move compute closer to the data than ever, and how computational storage is enabling a new approach to storing and managing data.
Any re-use permitted for informational and non-commercial or personal use only.
Editorial Contact


Latest on X
We were delighted to welcome H.R.H. Prince Daniel and the inspiring entrepreneurs from Prince Daniel’s Fellowship to Arm Cambridge!🙌
Great conversations, bright ideas, and lots of energy around the future of innovation.
Thanks for spending the day with us! 🤝




It started in karting. Now, @1jessicahawkins is chasing the toughest race in the world, Le Mans.
Fueled by determination and innovation, and supported by the @AstonMartinF1 team and Arm.
This is Jessica's story.
🎥 Watch now: https://shorturl.at/GfycI

5 cities. 1 vision. 👏
Arm Unlocked 2025 in Shanghai, Shenzhen, Seoul, Taipei, and Tokyo brought the global ecosystem together to define how AI scales, from edge and physical AI to cloud AI, all on the Arm compute platform.
https://okt.to/q3PXFU

What’s your favorite way to celebrate milestones at work?
35 years of innovation. 35 years of people shaping the future of computing. 💪
Our offices around the world celebrated 35 years of Arm in true style — connection, creativity, and (of course) cake 🎉

Today, we're celebrating 35 years of Arm! 🎉
That makes us old enough to remember dial-up, and young enough to be at the leading edge of AI.
Arm technology touches 100% of the connected global population, with more than 325 billion chips shipped worldwide.…

This week, we're celebrating 35 years of Arm! 🎉
That makes us old enough to remember dial-up, and young enough to be at the leading edge of AI.
Arm technology touches 100% of the connected global population, with more than 325 billion chips shipped worldwide.…

Mohamed Awad, EVP of Cloud AI Business Unit at Arm, recently joined Silicon Valley Tech Talks to discuss how AI is reshaping data centers, and how Arm’s Neoverse and Arm Total Design ecosystem are helping the industry meet the growing demands of compute.
Arm's Innovations for AI Infrastructure
...
okt.to
Collaboration drives impact. 📷
Over the past decade, we've partnered with @UNICEFinnovate
to apply technology for good, developing scalable AI solutions to protect children’s health, advance education, and build climate resilience.
Discover the story @FT:…
#MSIgnite may be over but if you missed us there's no need to worry.
Head over to our Cloud Migration Hub or Developer Program resources to learn more about the future of cloud computing on Arm. 💪 https://okt.to/gTJ8qj

Inspired by #SC25? So are we.
From record-breaking Arm-based supercomputers to powerful new innovations in AI and HPC, the future of compute is being built on Arm.
Be part of what’s next 👉 http://careers.arm.com




From building networks to shaping the AI era, @AristaNetworks’ Jayshree Ullal joins Rene Haas on the Tech Unheard podcast to talk bold moves, software-first thinking, and leading through change in the AI era.
Listen to the new episode now: https://okt.to/9dEpyc 🎧

Micosoft Azure Cobalt 100 VM powered by Arm Neoverse deliver up to 99% better price-performance across workloads. From web infrastructure to quantitative finance, these instances are enabling efficiency, scalability, and real-world value .
Built on Arm - redefining the future.…

📢 Introducing Cobalt 200!
In partnership with @Microsoft we're bringing you the first publicly announced silicon built on the Arm Neoverse Compute Subsystem V3 (CSS V3).
A vital part of our commitment to a more efficient, scalable, and sustainable cloud!…

👋 Good morning from #SC25!
Stop by the Arm booth to explore our latest demos, connect with our talent team, and learn about open roles and life at Arm.
💡 Discover how you can help shape the future of AI and HPC — and be part of the team driving the future of compute! 📍#4425



🚀 We kicked off #SC25 with @AWSCloud & @NVIDIA, bringing the Arm HPC & Advanced Compute community together to connect and share their experiences building on Arm.
With every major hyperscaler choosing Arm, we’re powering the future of AI and supercomputing. See you at the show!

Our partnership with @NVIDIA keeps growing. 🤝
By extending Arm Neoverse with NVIDIA NVLink Fusion, we’re enabling partners to achieve Grace Blackwell-class performance, bandwidth, and efficiency — delivering greater intelligence per watt for the AI era.
https://okt.to/PHg461

The Fujitsu A64FX powered Fugaku supercomputer showed what was possible with Arm architecture. FUJITSU-MONAKA shows what’s next.
Available in 2027, it brings supercomputing innovation to data centers and the edge, combining SVE2 acceleration and our confidential computing…

Arm is powering the future of cloud computing for the AI and enterprise era.⚡
Whether you’re at #MSIgnite in person or online, don't miss our our on-demand session to learn more about how we're enabling performance, efficiency and innovation.
https://okt.to/Jy5ERg

AI, cloud-native, and multi-architecture design are transforming how workloads are deployed and scaled. The momentum seen at KubeCon + CloudNativeCon 2025 reflects an industry building for flexibility, performance, and efficiency - powered by Arm.
https://okt.to/QuhlMj

Counting down the days until #SC25!
From Fugaku to Jupiter, discover why the world's most advanced supercomputers and AI systems run on the Arm compute platform.
👇 Here's where you'll find us.

AI is changing what’s possible within robotics innovation. 🤖🧠
Recently Anders Beck, VP of Technology at @Universal_Robot, joined the Arm Viewpoints podcast and shared his thoughts on how AI is driving a more flexible, collaborative era of automation.
https://okt.to/IXWvYn

Some inventions don’t just break boundaries, they redefine what’s possible.
The Arm-based Meta Ray-Ban Display AI glasses and EMG wristband are changing how we interact with technology — no touchscreens, no buttons, just movement.
Congrats to the team at @Meta behind the…
KubeCon + CloudNativeCon highlights just how quickly the cloud-native ecosystem is advancing. Developers everywhere are rethinking performance, scalability, and efficiency - across architectures - built on Arm.

KubeCon + CloudNativeCon 2025 shows the evolution of cloud-native systems and multi-architecture innovation. We're accelerating this shift by enabling scalable, efficient performance for AI and next-generation workloads across diverse architectures!
https://okt.to/KYaX5H







